Recursive Link Crawler
The Recursive Link Crawler was created to better utilize the Trie class that I previously learned.
Functionality
The Recursive Link Crawler traverses a given link, gathering all subsequent links recursively. It builds a Trie structure representing the website's link tree.
Components
- TrieCrawler.py contains the main functionality of the program.
- Node.py handles background calculations and branching.
- Crawler.pyCreates and calls the TrieCrawler class with a specified website and title
Understanding Links and Nodes
In this context, a link is defined as any element with an HREF attribute, whether or not it is accessible. This means that not all links lead to valid websites. For example, ./styles.css is considered a node but not a reachable website.
Size Calculation and Scalability
The size of a Recursive Link Crawler (RLC) Trie is determined by the number of unique nodes it contains, not the number of links. Here’s an example:
-> Website 1 (Links to 2, 3, and 4)
- -> Website 2 (Links to 1)
- -> Website 3 (Links to 1 and 2)
- -> Website 4 (Links to 5 and 6)
- - -> Website 5 (Links to 4 and 2)
- - -> Website 6 (Links to 1 and 5)
In this case, the Trie would have a size of 6, as there are 6 unique websites, even though there are 11 total links.
It's easy to see how quickly this process can grow in complexity with any modern website. The following table provides examples of RLC sizes for different websites:
| Website | Link | RCL Size |
|---|---|---|
| Panoramic56 | Panoramic56/index.html | 11 |
| IBM | www.ibm.com/us-en | |
| Apple | www.apple.com | |
| The New York Times | www.nytimes.com | |
| The University of Utah | www.utah.edu | |
| Snowbird | www.snowbird.com |
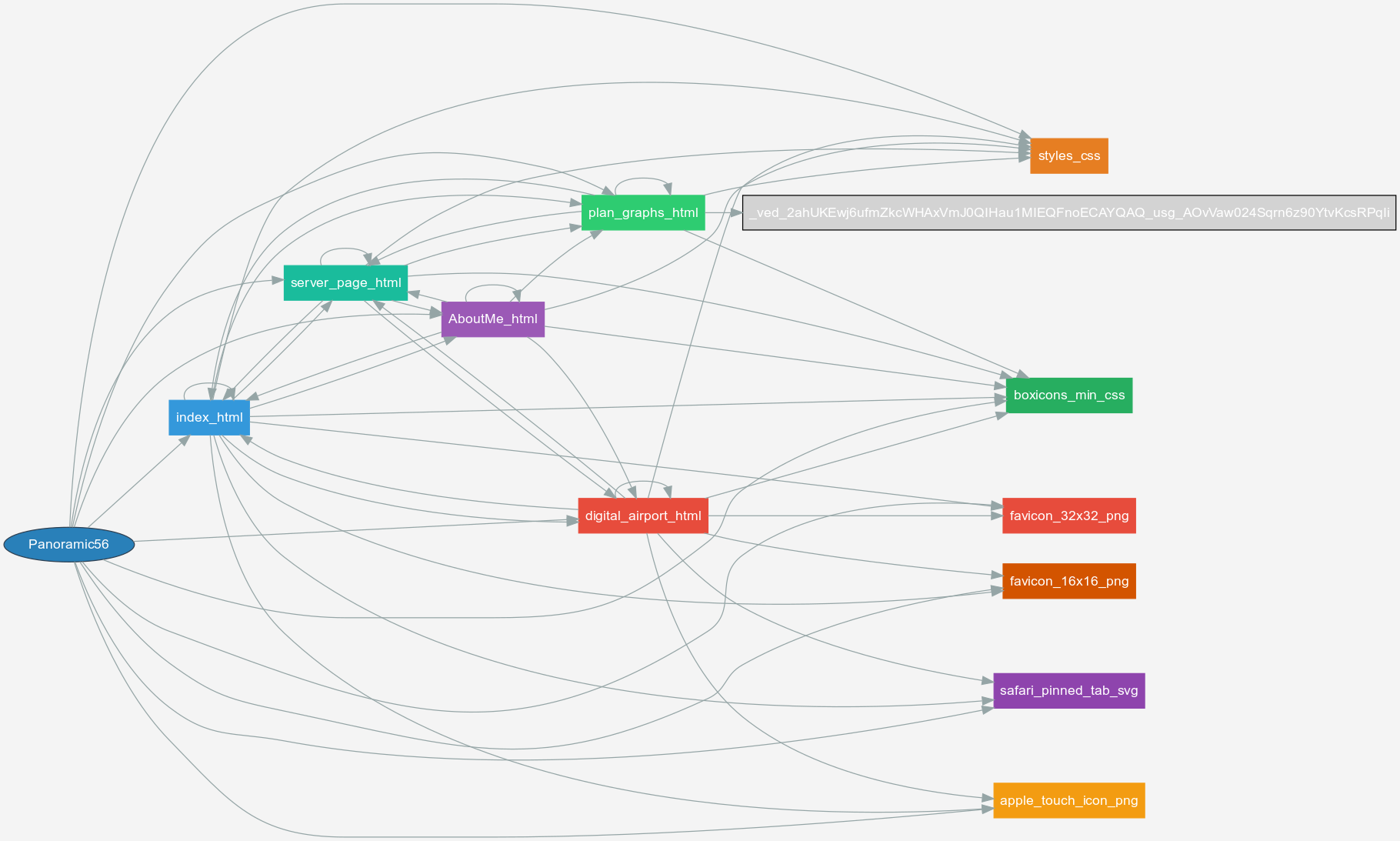
Dot Graphs
I decided to add a dot graph representation for the websites I was scrapping
The creation of these dot graphs is done based on the website title, which is the last section of the website's URL with it's punctuation changed to an underline (done in order to be compatible with GraphvizOnline
Since most of the websites have gigantic RCL Tries, the dot graph is almost unreadable, but for some smaller websites it is a good way of visualizing what the algorithm is doing
The following is a dot graph of my website (the grey box with the gigantic URL is the draw.oi website)
Conclusion
The time to scrape all these websites is significant, but optimizing web scraping is not the focus of this project. The goal is to understand the vast connectivity of the internet.
This was mostly a research experiment and not an actual, usable script
If you want to see the github repo where the code is stored, click the button below. The repo also has dot graphs for the example websites and their text representation
Recursive-Link-Crawler-